
A Common Language for EO Machine Learning Data


![]()
![]()
GitHub: https://github.com/IPL-UV/ML-STAC
Documentation: https://mlstac.readthedocs.io/
PyPI: https://pypi.org/project/mlstac/
Conda-forge: https://anaconda.org/conda-forge/mlstac
Tutorials: https://mlstac.readthedocs.io/en/latest/tutorials.html
Explicit is better than implicit.
Flat is better than nested.
Optimized storage saves more than just space.
Special cases aren't special enough to break the rules.
Dive directly into analysis, data always must be on demand
Overview 📜
ML-STAC provides a unified structure for cataloguing, describing, and adapting Earth Observation (EO) datasets into a format optimised for training Machine Learning (ML) models. Check the simple usage of mlstac here:
import mlstac
# Create a Dataset using the ML-STAC specification
json_file = "https://huggingface.co/datasets/jfloresf/demo/raw/main/main.json"
train_db = mlstac.load(json_file, framework="torch", stream=False, device="cpu")
print(train_db[4])
# {'input': tensor([[[ 6.3199, 6.3629, 6.4148, ..., 10.4104, 10.5109, 10.3847],
# [ 6.3850, 6.3615, 6.4166, ..., 10.4540, 10.4384, 10.4554],
# [ 6.3519, 6.3176, 6.3575, ..., 10.4247, 10.4618, 10.4257]]]),
# 'target': tensor([[[ 6.3199, 6.3629, 6.4148, ..., 10.4104, 10.5109, 10.3847],
# [ 6.3850, 6.3615, 6.4166, ..., 10.4540, 10.4384, 10.4554],
# [ 6.3519, 6.3176, 6.3575, ..., 10.4247, 10.4618, 10.4257]]])
# }
ML-STAC is strongly influenced by the STAC specification and its extensions, single-file-stac (Deprecated), TrainingDML-AI and ML AOI. Additionally, we have incorporated naming conventions as discussed in the OGC Training Data Markup Language - AI Conceptual Model Standard.
Is ML-STAC an STAC Extension? 🤔
Within the ML-STAC specification, each dataset is treated as an STAC Collection. Learn more at STAC-ML. However, each sample or element within that dataset is not considered an STAC Item. Instead, we propose a new data structure called ML-STAC Sample, which is optimized for efficient read access to a wide range of data types, including images, text, and video.
The ML-STAC specification 📋
The ML-STAC Specification consists of 2 interrelated specifications.
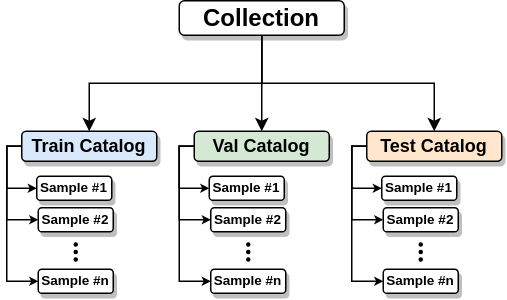
- ML-STAC Sample is the core atomic unit, representing a single data sample as safetensor file.
- ML-STAC Collection, is an extension for STAC Collections that aggregates information about ML tasks, licenses, providers, and more. Each ML-STAC Collection must contain three Catalog objects: train, validation, and test.
Additionally, the ML-STAC specification includes an API interface, giving users on-demand access to datasets that conform to the ML-STAC specification.
How can I adapt my dataset to align with the ML-STAC specification? 🔧
The process is straightforward for the vast majority of EO ML datasets. Here are the typical steps we follow.
- Check to which ML Task your dataset fixes better, we currently support more than 10 different tasks including multi-modal cases.
- Create a generic dataloader (iterator object) using your favourite framework.
- Use the ml-stac toolbox and the iterator object (from step 2) to create safetensors easily.
- Move your dataset to your favourite file storage system (e.g. Local, AWS S3, Hugging Face Datasets, Azure Blob Storage, etc.).
- Create a ML-STAC Collection object. We highly recommend you use
mlstac.collection.datamodelvalidators. - Success! Remember that
mlstacis multi-framework, so you can load your dataset in your favourite framework without needing additional dependencies (we currently supporttorch,tensorflow,paddle,jaxandnumpy).
Installation 🚀
Install the latest version from PyPI:
pip install mlstac
Upgrade mlstac by running:
pip install -U mlstac
Install the latest version from conda-forge:
conda install -c conda-forge mlstac
Install the latest dev version from GitHub by running:
pip install git+https://github.com/ipl-uv/mlstac
Contributing 🤝
We welcome and encourage anyone interested in improving or expanding the ML-STAC specification to join our collaborative efforts. Before becoming a part of our community, kindly familiarize yourself with our contribution guidelines and code of conduct.
License 🛡️
The project is licensed under the GNU General Public License v3.0.
Acknowledgment 📖
This project has been made possible thanks to the collaboration between 5 research groups: Image & Signal Processing (ISP), the Remote Sensing Centre for Earth System Research (RSC4Earth), the Information Technologies for the Intelligent Digitization of Objects and Processes (TIDOP), the High Mountain Ecosystem (EcoHydro), and the Ecotoxicology Laboratory (EcoLab). We received funding from the National Council of Science, Technology, and Technological Innovation (CONCYTEC, Peru) under the “Proyectos de Investigación Básica – 2023-01” program (PE501083135-2023-PROCIENCIA).
